Using the OneCompute Result Lake
- Result Lake Overview
- How to store output files in Result Lake
- How to download files from Result Lake
- See also
Result Lake Overview
The purpose of the OneCompute Result Lake is to enable OneCompute Platform to efficiently run large compute jobs that need to persist many large result files, each possibly many GBs of size, while running at high scale and without significant delays in the storage process.
The OneCompute Result Lake service solves this problem by managing a pool of Storage Accounts. The Result Lake service
multiplexes file storage by allocating storage for different work units to different Storage Accounts, thereby spreading the load on all
storage accounts in the pool. Result Lake keeps a record of which storage account contains the results of each work unit.
The allocation is done just in time after the application worker has completed execution. At that point, the OneCompute WorkerHost will
make a request to the Result Lake service to allocate storage for the work unit. The WorkerHost will then upload the result files
to the allocated storage account. The files will be stored in a a blob container in the storage account that is allocated to the user.
The main difference between storing result files in the Result Lake storage and storing the same files in the normal user container,
is that Result Lake dictates a top level directory structure down to the work unit level. Result files from a particular work unit will
always be found in a directory named {jobId}/{workUnitId}. For the default user blob container, the client application
is in full control of its structure. OneCompute does not mandate any structure in that container.
Notice that the Result Lake service does not have a public API. Clients can only get access to files stored in Result Lake through the public OneCompute Platform API.
The following diagram depicts how the Result Lake Service allocates different storage accounts to different work units to spread the storage loads across all storage accounts in a storage pool.
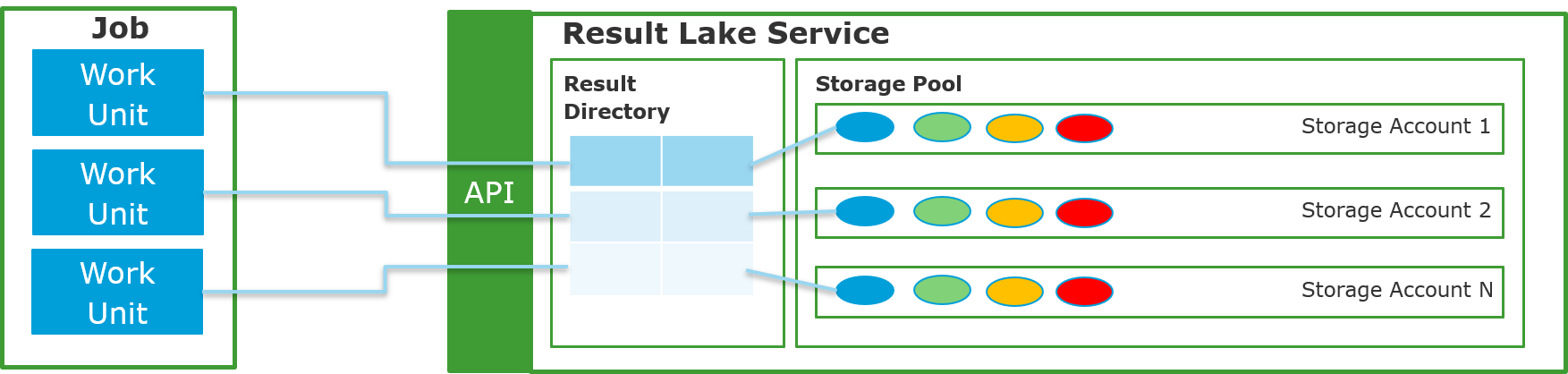 Figure: Result Lake service
Figure: Result Lake service
How to store output files in Result Lake
The usage of Result Lake is completely controlled by the client application. This is similar to how the client application also controls the standard user blob container and how it can be used to store result files from jobs. The only difference between the two cases is how the WorkUnit.OutputFileSpecifications property is defined. Instead of assigning a BlobDirectorySpecification to the FileTransferSpecification.DestinationSpecification property, a ResultLakeStorageSpecification should be used when a client application wants to use the Result Lake to store the output files from a job.
The following code example shows how to create a FileTransferSpecification that specifies that the output files for a WorkUnit should be stored in Result Lake:
var fts = new FileTransferSpecification
{
SourceSpecification = new FileSystemDirectorySpecification(),
DestinationSpecification = new ResultLakeStorageSpecification()
};
How to download files from Result Lake
Files can be downloaded from Result Lake in exactly the same way as from the default user container, see Managing Files with OneCompute Platform.
The only difference is how the container URI is retrieved. When the output files for a particular work unit has been stored in Result Lake,
the OneComputePlatformClient.GetWorkItemStorageContainerUriAsync
must be used to get the container URI. This method takes three arguments; the job id, the work unit id and the container name to get access to.
The container name is the name of the user container and can be retrieved by calling OneComputePlatformClient.GetContainersAsync
in the same way as for the default user container, see Managing Files with OneCompute Platform.
It is necessary to specify the source directory of the download as described above: {jobId}/{workItemId}.
The following code example shows how to create a FileTransferSpecification.DestinationSpecification
for downloading from Result Lake:
// The container name for a particular user is always the same
var containerUri = await oneComputePlatformClient.GetWorkItemStorageContainerUriAsync(jobId, workItemId, userContainerName);
var fts = new FileTransferSpecification
{
SourceSpecification = new BlobDirectorySpecification
{
ContainerUrl = containerUri,
Directory = $"{jobId}/{workItemId}"
},
DestinationSpecification = new FileSystemDirectorySpecification() // Download to current directory
};